Recognition rate e false positive rate: due indici da conoscere nel mondo della lettura ottica
Quando si parla di lettura ottica, si affronta un tema ancora poco conosciuto per molti è la disinformazione regna sovrana. È così che si finisce per spendere elevate quantità di denaro a fronte di un risultato scarso. Oggi, l’offerta sul mercato di sistemi di lettura ottica è davvero molto ampia, www.datasis.it ne è un ottimo esempio.
Software house italiane e straniere propongono applicativi di tipo verticale o general purpose, ciascuno dotato di proprie caratteristiche e peculiarità che lo rendono più o meno appetibile. L’obiettivo è lo stesso ciò che varia è in particolare la nitidezza con cui vengono digitalizzati i documenti, la velocità e la facilità di accesso.
Sebbene le attività svolte da tali sistemi si possano solitamente suddividere in acquisizione dei documenti, riconoscimento, correzione ed output dei dati, non tutti i sistemi lavorano allo stesso modo e non tutti hanno le stesse prestazioni. Inoltre anche il range di prezzi è molto ampio e può contribuire a confondere maggiormente le idee.
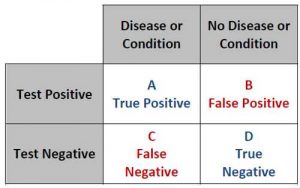 Il primo elemento da valutare è il recognition rate ma è comunque un parametro da prendere con le pinze. Si tratta, in sostanza, della percentuale di dati riconosciuti correttamente dal sistema. Molti promuovono sistemi sostenendo di aver raggiunto il 99% di recognition rate ma, purtroppo, non si tratta di un’informazione affidabile.
Il primo elemento da valutare è il recognition rate ma è comunque un parametro da prendere con le pinze. Si tratta, in sostanza, della percentuale di dati riconosciuti correttamente dal sistema. Molti promuovono sistemi sostenendo di aver raggiunto il 99% di recognition rate ma, purtroppo, non si tratta di un’informazione affidabile.
Ad esempio se due venditori affermano entrambi che il proprio sistema di lettura ottica ha un recognition rate del 99%, potrebbe essere certamente vero che ciascuno su un proprio campione di documenti abbia raggiunto quel risultato, ma non è detto che i due sistemi offriranno le medesime prestazioni sui propri documenti. Infatti ciascuno avrà utilizzato un campione diverso dall’altro per determinare la stima, quindi i due numeri non possono essere comparabili né ovviamente possono dare alcuna futura garanzia.
Il primo gruppo di documenti potrebbe avere per esempio un numero minore di caratteri speciali, potrebbe avere un carattere più grande, più chiaro, essere scritto in una sola lingua e così via. L’unico modo per utilizzare il recognition rate come feature di comparazione potrebbe essere quello di eseguire un test sul medesimo campione di documenti, ma anche in questo caso ci sono ulteriori implicazioni da tener presente.
È qui che dobbiamo inserire il concetto di false positive rate ovvero la percentuale dei dati letti male ma considerati comunque accettabili. Infatti ogni volta che un dato viene letto, gli viene attribuito una confidenza di lettura che indica quanto il sistema è certo di averlo letto correttamente, ed in base ad una soglia su questo valore, si può stabilire se il dato necessita di validazione da parte di un operatore oppure no.
In sostanza, si rivela migliore un sistema che riconosce di aver letto male una percentuale maggiore di parole rispetto a un altro che non riesce neppure a riconoscere di aver letto male quelle stesse parole. In sostanza il paragone si può fare colo con un campione identico di testi da digitalizzare poi sottoposti a un giudizio umano.
Ma quali aziende consentono di fare tutto ciò? Praticamente nessuna perciò quando si sta per acquistare un macchinario o quando ci si sta per rivolgere a qualcuno per digitalizzare il proprio archivio questi due parametri devono essere senz’altro presi con le pinze.

5 Errori classici nella realizzazione di un sito web

Pronto al lancio il nuovo Surface Pro di Microsoft
